
Find Solutions in Our Knowledge Base
The robots.txt file is a straightforward textual content file positioned in your internet server which tells internet crawlers that if they need to entry a file or not. The robots.txt file controls how search engine spiders see and work together along with your webpages. Attributable to improperly configured ROBORTS.TXT information, the search engine is prevented from indexing an internet site. Additionally, the robots file is used to dam the search engine from indexing an internet site. It might additionally forestall an internet site from being listed on a search engine.
In some circumstances, this bots hits in your web site after which it consumes quite a lot of bandwidth and on account of this your web site will decelerate. It is rather vital to dam such bots to stop such conditions. There’s a likelihood to get quite a lot of visitors in your web site which might trigger issues resembling heavy server load and unstable server. Putting in Mod Safety plugins will forestall most of these points.
Correcting the Robots.txt from Blocking all web sites crawlers
The ROBOTS.TXT is a file that’s sometimes discovered on the doc root of the web site. You possibly can edit the robots.txt file utilizing your favourite textual content editor. On this article, we clarify the ROBOTS.TXT file and discover and edit it. The next is the widespread instance of a ROBOTS.TXT file:
Consumer-agent: *
Disallow: /
The * (asterisk) mark with Consumer-agent implies that every one engines like google are allowed to index the positioning. By utilizing the Disallow choice, you’ll be able to limit any search bot or spider for indexing any web page or folder. The “/” after DISALLOW signifies that no pages might be visited by a search engine crawler.
By eradicating the “*” from the Consumer-agent an additionally the “/” from the Disallow choice, you’re going to get the web site listed on Google or different search engine and in addition it permits the search engine to scan your web site. The next are the steps to modifying the ROBOTS.TXT file:
1) login to your cPanel interface.
2) Navigate to the “File Supervisor” and go to your web site root listing.
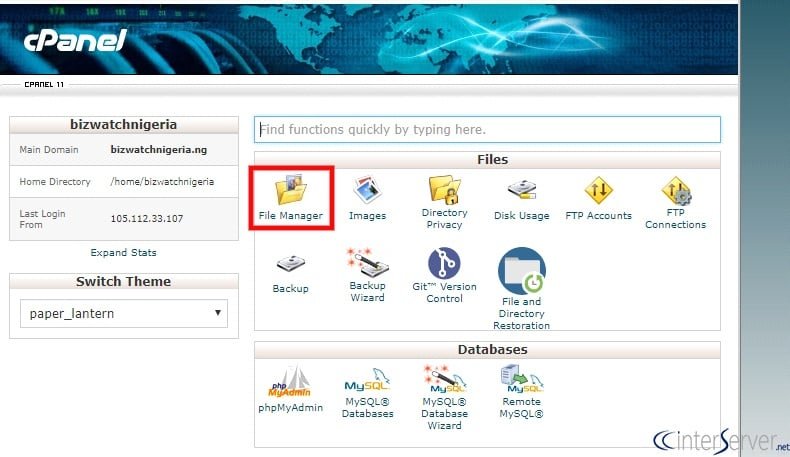
3) The ROBOTS.TXT file needs to be in the identical location because the index file of your web site. Edit the ROBOTS.TXT file and add the under code and save the file.
Consumer-agent: *
Disallow: /
You too can block a single unhealthy Consumer-Agent in .htaccess file by including the under code.
RewriteEngine On
RewriteCond %HTTP_USER_AGENT Baiduspider [NC]
RewriteRule .* – [F,L]
In case you wished to dam a number of Consumer-Agent strings without delay, you might do it like this:
RewriteEngine On
RewriteCond %HTTP_USER_AGENT ^.*(Baiduspider|HTTrack|Yandex).*$ [NC]
RewriteRule .* – [F,L]
You too can block particular bots globally. To do that please login to your WHM.
You then would want to navigate to Apache Configuration >> Embrace Editor >> go to “Pre Predominant Embrace” >> choose your apache model (or all variations) >> then insert the code under and click on Replace after which restart apache.
<Listing “/house”>
SetEnvIfNoCase Consumer-Agent “MJ12bot” bad_bots
SetEnvIfNoCase Consumer-Agent “AhrefsBot” bad_bots
SetEnvIfNoCase Consumer-Agent “SemrushBot” bad_bots
SetEnvIfNoCase Consumer-Agent “Baiduspider” bad_bots
<RequireAll>
Require all granted
Require not env bad_bots
</RequireAll>
</Listing>
It will undoubtedly scale back the server load and can provide help to to enhance your web site efficiency and velocity.
In case you want any additional assist, please do attain our assist division.
cPanel / WHM
- All about cPanel Customization
- All about cPanel Proxy Tool
- All About cPanel Solo License
- All about CSF Messenger Service
- All about new feature – Domains interface in cPanel
- Automated Email Archiving in Roundcube
- Backup Exim Configuration
- Block Email from a Country or Domain in cPanel
- cPanel Calendars and Contacts – CardDAV/CalDAV
- cPanel Horde Data Conversion from MySQL to SQLite
- cPanel Log Rotation Configuration
- cPanel Plugin File Generator
- cPanel Price Increase And Alternative Control Panels
- cPanel/WHM – WHMCS Integration
- cPanel’s Email Deliverability Interface
- Create Website with RVSiteBuilder in cPanel
- Email Account Password Reset in cPanel
- Email Account Password Reset in cPanel and Webmail
- Email Archiving on cPanel Server
- Email Migration to cPanel Using Outlook
- Enable Force Password Change for cPanel Accounts
- Enable or Disable cPanel Analytics Feature at the User Account Level
- Enable Terminal Application for cPanel
- Error While Adding Addon Domain in cPanel
- Everything about cPanel Web Disk
- File Restoration in cPanel v68
- Find the Origin of Spam Emails in cPanel Using Exim
- Find the Potential Spammer Account in cPanel/Exim
- Fix cPanel FTP Failed to retrieve Directory Listing Error
- How to Add cPanel/WHM Server on WHMCS?
- How to Block Bots using Robots.txt File?
- How to change cPanel logout URL
- How to Change cPanel Style
- How to Change URL of the Joomla Website in cPanel?
- How to Clone a Git Repository in cPanel?
- How to Configure Email Routing in cPanel
- How to Copy Locales in cPanel and WHM?
- How to Disable AutoSSL Email Notifications from cPanel
- How to Disable cPanel, Webmail, WHM shortcut URLs
- How to Disable eximstats_spam_check Notifications
- How to Edit Locales in cPanel & WHM?
- How to Enable Leech Protection in cPanel?
- How to enable memcached on cPanel shared hosting at WebHostingPeople
- How to Enable/Disable Cachewall from cPanel Account?
- How to Host Git Repositories on a cPanel Account
- How to Increase the Upload Size of MySQL Database in PhpMyAdmin on a cPanel Server?
- How to Install BigTree in cPanel/WHM Server?
- How to Install Concrete5 Manually in cPanel Server
- How to Install Redis and PHP-Redis on cPanel
- How to Locate Your Email Settings in Webmail and cPanel
- How to manage and install Patchman in cPanel
- How to manage API Tokens in cPanel
- How to Manage Email Accounts Suspension in cPanel?
- How to Optimize MySQL Database Using phpMyAdmin in cPanel?
- How to Overcome FTP Max Connection from a Single IP in WHM/cPanel?
- How to Replace MySQL With MariaDB on a cPanel Server?
- How to Reset cPanel Password of an Account from WHM?
- How to Reset cPanel Password?
- How to Reset MySQL Root Password and Restore Database Grants in cPanel Server?
- How to Uninstall AutoSSL for an Addon Domain
- How to View Archived Emails via Webmail?
- Importing Email Accounts using a CSV or Excel File in cPanel
- Importing Email Forwarders using a CSV or Excel File in cPanel
- Install ConfigServer MailScanner on cPanel Server
- Install ConfigServer ModSecurity Control in cPanel
- Install Matomo Self-Hosted Analytics on cPanel
- Install RVSiteBuilder on cPanel and DirectAdmin
- Install SitePad Website Builder in cPanel
- Installing Softaculous on a cPanel Server
- Login to WordPress Dashboard From cPanel
- Manage Email Accounts Suspension in cPanel?
- Manage NodeJS Through cPanel
- Manage Reseller’s IP Delegation in cPanel
- Managing Suspended Accounts in WHM
- Message Highlighting in SquirrelMail
- Migrate cPanel Account from cPanel to CWP
- Migrate Email Accounts from Zoho to cPanel
- Migration from cPanel to Webmin/Virtualmin
- Modify cPanel & WHM News
- Modify IP Block Checking Time Interval in CSF
- Multi Account Functions in cPanel
- New cPanel feature – Backup User Selection
- PageSpeed on cPanel Server
- Permanent Redirection Rules in .htaccess File
- RainLoop Webmail on cPanel
- Reset MySQL Installation in cPanel
- Sent Attachments not showing in Horde Webmail?
- Setting up Railgun on cPanel
- Setup Autoresponder in cPanel webmail
- Setup BoxTrapper in Webmail
- Softaculous Staging Environment
- Some Steps to Reduce Disk Space on cPanel Server (For VPS/Cloud Clients Only)
- SSL/TLS Status feature in cPanel
- The management of domains in the cPanel Jupiter theme
- The New HTTPS Redirection Feature in cPanel
- Unable to Access PhpMyAdmin in cPanel
- What is mod_pagespeed and how to enable it?
- What steps should I take when my browser displays a certificate error while trying to access WHM/cPanel or Plesk control panel?
- Show all articles (83) Collapse Articles
Email Tutorial
- About Email Policy, Email Quota and Email Limits
- About Zimbra-Email Server Collaboration
- Access Emails
- All about Junk Email Filter
- All You Need to Know About Email Reputation
- Can I change the MX records on my account?
- Configure Mail Settings in Joomla
- Configure the Number of Outgoing Messages in Plesk
- cPanel Email Encryption Explained
- Customize Exim System Filter File
- Difference Between Maildir and Mbox's Directory Structure
- Disable Email Notifications Sent by Softaculous
- Dovecot - A detailed explanation
- Email Accounts - WebHostingPeople Tips
- Email Client Configuration
- Email Deliverability in WHM
- Email Greylisting. How does greylisting work?
- Email Management in Plesk
- Enable Email Alerts in Keepalived
- Error when sending email
- Exactly How Emails Works - Steps and Explanation
- Extended Exim Logging
- Features and Details of Qmail MTA
- Forward Domain’s email to Gmail
- Gmail MX Record Changes
- Guaranteed Email Delivery
- Handle Bounce Back Emails in phpList
- How to Add an Email Account in Webuzo?
- How to Automatically Empty Trash Folder for Mails
- How to Backup and Restore Emails in Roundcube
- How to Ban Emails in phpBB
- How to Check if an Email Address Really Exists Without Sending an Email
- How to Clear Default Mail Account in a cPanel Server
- How to configure Email in Mac?
- How to Configure Email Piping in WHMCS?
- How to create catch-all email address in cPanel
- How to Disable Mass Mail in Joomla?
- How to Enable Outgoing Spam Filtering Using SpamAssassin?
- How to Fix the Error “The mail server detected your message as spam and has prevented delivery”?
- How To Install Postfix From Source
- How to Install SpamAssassin, MailScanner, ClamAV in CentOS Mail server
- How to Limit Emails Per Hour in WHM?
- How to Resolve the Outlook Error 0x800ccc0b When Sending Emails
- How to Send Bulk Email to Customers in Plesk
- How to Set Mail Server in DirectAdmin?
- How to setup and configure SMTP Server on Windows Server 2008 R2
- How to Setup Email Forwarding in Webuzo
- How To Stop Email Going To Recipients Spam Box?
- How to Use Google’s Free SMTP Server
- Important Postfix Configuration Settings
- Linux Mail Command Usage with Examples
- LMTP ( Local Mail Transfer Protocol ) in cPanel
- Mail Delivery Reports in WHM
- Mailbox Conversion in WHM
- MailChannels common mail bounce back errors
- Mailing Lists - WebHostingPeople Tips
- Mailman bounces emails with Unroutable Domain
- Manage Banned Emails in WHMCS
- Manage Email Accounts in cPanel
- Manage Email Disk Usage in cPanel
- Manage Email Marketer in WHMCS
- Manage Email Templates in WHMCS
- Manage Exim Mail Queue in WHM
- Manage Mass Mail Tool in WHMCS
- Mass Email Settings in phpBB
- Mass Mail Setup and Configuration in OpenCart
- MOJO Mail tells me Inappropriate ioctl for device
- My SMTP port 25 is Blocked by my ISP
- Neomail shows no messages even though I can see them through pop and imap
- Outlook Email Being Sent "On Behalf Of"
- Processing Email With Procmail
- Reset Mailman Password from WHM
- Restore Exim Configuration
- Set up Email Account in Thunderbird
- Set up Mail Fetching at Gmail
- Set up Mail Fetching at Hotmail
- Setup Email Account in Microsoft Outlook
- SMTP Status Codes and Meanings
- Spam Assassin - WebHostingPeople Tips
- Spam Filter Settings in Plesk
- Spam Prevention Methods in cPanel
- SPF and DKIM Records - Detailed Overview
- Thunderbird error: weak ephemeral Diffie-Hellman key error
- Tips to Block Email Spam with Postfix SMTP Server
- Track Delivery of Email in cPanel
- Types of Email Marketing
- Understanding Bounce Back Emails
- Useful Exim Commands with examples
- WebHostingPeople Email Account Settings
- What can I do to reduce SPAM?
- What is a Proper Email Structure?
- What is MailChannels Cloud
- What is MIME ( Multi-Purpose Internet Mail Extensions )
- What is my POP server?
- What is Sendmail? Sendmail Configuration and Details
- What is SpamAssassin?
- When using PINE what should the SMTP setting be?
- Show all articles (82) Collapse Articles
General
MySQL
- Allow Remote IP Address to Access MySQL in cPanel Shared Hosting
- AutoMySQL Backup installation and configuration on Centos
- C.5.2.4. Client does not support authentication protocol with php selector
- Database Management in Plesk
- DEFAULT CHARSET=latin1 or collate latin1_general_ci NOT NULL default or TIMESTAMP errors on importing a database dump
- Disable MySQL Strict mode
- Edit MySQL Config
- Establishing a Connection to a MySQL Database with PHP on Linux Hosting
- Here is a guide on optimizing your MySQL database using phpMyAdmin in Plesk.
- How can I backup my MySQL Database?
- How can I increase MySQL max connections?
- How can I start and stop mysql?
- How do I allow remote MySQL connections?
- How to backup a MySQL database using PhpMyAdmin
- How to Change MySQL Server Time Zone
- How to configure Master-Master replication in MySQL on Ubuntu
- How to Create a DB(DataBase) using the MySQL Database Wizard in cPanel
- How to Create and Manage FTP Accounts in VestaCP
- How to Install LAMP Stack on Ubuntu / Debian
- How to Install MySQL on CentOS 7
- How to install Nginx, MySQL, and PHP (LEMP stack) on Ubuntu 16.04
- How to Prevent an SQL Injection Attacks and Remote Code Execution
- How to recover the mysql root password?
- How to Repair Databases in cPanel
- How to Reset MySQL root password in Ubuntu
- How to Run MySQL Query in phpMyAdmin
- How to upgrade MariaDB from version 10.0 to 10.3 on Ubuntu 16.4
- How to use MYISAMCHECK and MYSQLCHECK and what they are used for
- How to use the Command Line to Import and Export Databases in MySQL
- I get incorrect root password when accessing a MySQL Cpanel feature
- Importing .sql file in MySQL via command line and phpMyAdmin
- Install MariaDB in Linux Server
- Installation and Details of MySQL Pinba storage engine
- Installation of NexusCore and SQL Server 2017 in WHM
- Installation of XAMPP in Linux and Windows
- Managing MySQL databases using the command line
- Managing MySQL users through the command line
- MySQL Error - The Server Quit Without Updating PID File
- MySQL FLUSH Commands
- MySQL Storage Engines - Types and Details
- OwnCloud: The Private Cloud-Installation Guide
- PHPMyAdmin shows every database when logging in as a user
- PostgreSQL Availability
- Securing MySQL connections using SSL on Ubuntu
- Steps to Install and Setup PhpWiki
- The comprehensive manual for mysqldump - An efficient program for backing up databases
- The size of MySQL databases is displayed as 0MB in cPanel
- To enable remote connections to MySQL and secure them on Ubuntu 16.04
- To set up Master-Slave replication in MySQL Server 5.7
- Understanding Mambo CMS
- What is MySQL Query Caching?
- Where can I access additional resources about MySQL?
- Show all articles (37) Collapse Articles
Security
Technical
WebSitePanel
Direct Admin
- Access denied for user da_admin – MySQL error in DirectAdmin
- Add Custom PHP Modules with Custombuild in DirectAdmin
- Add Reseller Account in DirectAdmin
- Autodiscover Information For Mail Clients in DirectAdmin
- Backup Management in DirectAdmin
- DirectAdmin dead but subsys locked Error
- DirectAdmin Installation
- DirectAdmin Password Reset or Recover Options
- Directory Structure of DirectAdmin Explained
- DNS Management in Direct Admin
- Enabling Multiple PHP versions On DirectAdmin
- FTP Management in DirectAdmin
- Hostname and the servername you have set in DirectAdmin, do not match
- How to change the domain name in DirectAdmin
- How to Install a Free Let's Encrypt SSL Certificate on DirectAdmin
- How to Install Nginx on DirectAdmin
- How to install suPHP on DirectAdmin
- How to manage Autoresponders in DirectAdmin
- How to Use IPv6 Address in DirectAdmin
- Important Log File Locations in DirectAdmin
- Install Laravel on a DirectAdmin Server
- Install mod_ruid2 on DirectAdmin
- Install Redis and Redis-PHP in DirectAdmin
- Install SitePad in DirectAdmin
- Install SSL Certificate in DirectAdmin
- Install WordPress on DirectAdmin Using Installatron
- Install Zend OPcache in DirectAdmin
- LetsEncrypt Support in DirectAdmin Control Panel
- Manage Cron Jobs in Direct Admin
- Manage Email Accounts in DirectAdmin
- Manage SPAM Filters in DirectAdmin
- Migrate accounts from DirectAdmin to DirectAdmin
- MySQL Management in Direct Admin
- Reasons and Fixes for DirectAdmin License Expired Error
- Redirect Website /Path to Use HTTPS in DirectAdmin
- Set up DirectAdmin to Use a Remote MySQL Server
- Setup Domain in DirectAdmin
- SpamAssassin Setup in DirectAdmin
- The Best Web Hosting Control Panels – Overview
- Too Low or 0.00 Disk Usage in DirectAdmin
- Show all articles (25) Collapse Articles
WordPress
- 404 Error Page When Logging Into WordPress Admin Page
- About WordPress multisite and it’s features
- About WordPress Nonces
- Adding Audio and Video to Word Press Blog Post
- Adding language translations to your site
- Adding Official LinkedIn Share Button in WordPress
- Blogger to WordPress Redirection Using Plugin
- Change Time Zone in WordPress
- Change WordPress Admin Username from Dashboard
- Choosing a Gallery Plugin for your WordPress Site
- Create a Job Board Website with WordPress
- Create a Staging Site from WordPress Dashboard
- Create Local Business Website without a developer!
- Create Local Restaurant Website without a Developer
- Create New Admin Account in WordPress via MySQL
- Creating a hashed upload directory structure in wordpress for sites with large amounts of files
- Creating and Using Sitemaps: The Basics
- Disable WordPress Plugins via phpMyAdmin
- Easy Digital Downloads Plugin for WordPress
- Easy WP SMTP Plugin
- Enable Litespeed Cache for All WordPress Websites in cPanel
- Example of writing a simple WordPress Plugin
- Fix : WordPress has failed to upload. Unable to create directory.
- Fix the Mixed Content Issue on WordPress
- Fix WordPress Error – Sorry, This File Type Is Not Permitted For Security Reasons
- Free Hacked WordPress Cleanup
- Guide for Creating a Multi-Lingual Website
- How much does it cost to build a website
- How to Add a Bitcoin Donate Button to your wordpress blog?
- How to Add a Contact Form to Your WordPress Blog
- How to Add a PayPal Shopping Cart to Your WordPress Blog
- How to Add a Poll to Your WordPress Blog
- How to Add a Static Front Page to Your WordPress Blog
- How to Add a YouTube Video to Your WordPress Posts
- How to Add an Image Gallery to Your Sidebar in WordPress
- How to Add an RSS Feed to Your WordPress Blog
- How to Add and Manage Categories in WordPress
- How to Add Custom Images Sizes to WordPress
- How to Add Font Awesome Icons to Your WordPress Site?
- How to Add Google Analytics to WordPress?
- How to Add Google Maps to Your WordPress Blog
- How to Add Google Search to Your WordPress Site
- How to add HTML to a WordPress Page or Post?
- How to add Poll to WordPress
- How to Add Social Media Buttons to WordPress Posts
- How to Automatically Cross-Post Your WordPress Posts to Both Medium and LinkedIn Publishing
- How to Back Up Your WordPress Blog
- How to Change Footer Text in WordPress?
- How to Change Site Language in WordPress
- How to Change Site Title and Tagline in WordPress
- How to Change WordPress Site URLs (Best Methods)!
- How to Change WordPress Theme by Editing Database?
- How to change WordPress username?
- How to Check Your WordPress Site for Broken Links
- How to Choose a Page Builder for Your WordPress Site
- How to Clear WordPress Cache with W3 Total Cache and WP Super Cache?
- How to Configure Secure Updates and Installations in WordPress
- How to Configure WordPress Email to Use SMTP Server?
- How to Configure WordPress with External Database
- How to Correct Image Links After WordPress Migration
- How to Create a Favicon for Your WordPress Blog
- How to Create an Art Portfolio Website Using WordPress CMS?
- How to Create WordPress Theme
- How to Customize the 404 Page for Your WordPress Site
- How to Disable Pingbacks and Trackbacks in WordPress
- How to Disable Plugins in WordPress
- How to Disable RSS Feeds in WordPress?
- How to Disable Wp-Cron and Replace It with A Real Cron Job
- How to Enable a Maintenance Mode for Your WordPress Blog
- How to Enable or Disable WordPress Automatic Updates
- How to Enable PHP Error Log for WordPress Sites
- How to Enable Private Mode on WordPress Website?
- How To Fix “Error Establishing Database Connection” In WordPress
- How to Fix Render-Blocking JavaScript and CSS in WordPress
- How to Fix SMTP ERROR: Failed to connect to server: Connection refused (111) error on WordPress
- How to Fix the Japanese Keyword Hack in WordPress?
- How to Fix the WordPress Login Page Refreshing and Redirecting Issue
- How to Fix the WordPress White Screen of Death(WSoD)
- How to Fix Too Many Redirects Error in WordPress
- How to Fix WordPress Keeps Logging Out Error
- How to Force Logout All Users in WordPress?
- How to Install a Child Theme in WordPress
- How to Install a Theme on Your WordPress Blog
- How to Install AdSense on Your WordPress Blog
- How to Install Plugins in WordPress
- How to Install WordPress in ISPmanager?
- How to Install WordPress on Webuzo?
- How to Make Your WordPress Blog Pinterest Friendly
- How to Make Your WordPress Site Mobile-Friendly
- How to Make Your WordPress Site SEO-Friendly
- How to Manually Downgrade WordPress to The Previous Version?
- How to Moderate Reader Comments in WordPress
- How to Move WordPress to a New Domain without Affecting SEO
- How to Order Posts in Avada WordPress Theme
- How to Protect WordPress from XML-RPC Attacks
- How to Protect Your WordPress Blog from Spam with Akismet
- How to quickly change the wordpress site url editing wp-config.php
- How to Remove /wordpress/ from Your WordPress Blog URL
- How to Remove Tabs from the WordPress Administrator Dashboard
- How to Repair Database Through WordPress Dashboard?
- How to Reset WordPress Password?
- How to Reset Your Administrator Password in WordPress
- How to resolve “Could not write you may be over quota: Bad file descriptor” Error
- How to Restrict IP Addresses from Accessing WordPress Dashboard?
- How to scale a WordPress website
- How to Schedule a Post in WordPress
- How to Secure WordPress
- How to Set Permalinks in WordPress
- How to Set up Gravatar on WordPress
- How to set up High Availability WordPress with HyperDB
- How to set up Memcached on CentOS 6 and configure WordPress to use it
- How to Setup Redis Object Cache on a WordPress Site
- How to setup WordPress Two-Factor Authentication
- How to Show or Hide Widgets on Specific WordPress Pages
- How to Solve Leverage Browser Caching Warning in WordPress?
- How to Stop WordPress from Creating Additional Image Sizes
- How to Update WordPress
- How to Update WordPress Manually via FTP
- How to Use Widgets in WordPress
- How to use WordPress SEO by Yoast
- Install Avada Theme
- Install WordPress from Plesk
- Install WordPress Manually from cPanel
- Install WordPress on cPanel Using Site Software
- Install WordPress over SSH
- Install WordPress Theme Using FTP Client Filezilla
- Install WordPress using Softaculous in cPanel
- Install WordPress Using WordPress Manager
- Installation, Configuration and Features of Wordfence Security
- LiteSpeed Cache is Disabled Warning on WordPress
- Migrate a WordPress site from localhost to Ubuntu VPS
- Migrating from BlogSpot to WebHostingPeople WordPress Hosting
- Migrating from Weebly to WebHostingPeople WordPress Hosting
- Migrating from Wix to WebHostingPeople WordPress Hosting
- Move from WordPress.com to WebHostingPeople WordPress Hosting
- Prevent Brute Force Attacks in WordPress
- Remove Dashboard Access in WordPress
- Reset WordPress Admin Password Using Emergency Password Reset Script
- Secure WordPress Template for an WebHostingPeople VPS (PHPMMDROP)
- Setup Multiple WordPress Sites on one host a single VPS
- Short codes in WordPress explained
- The most common wordpress compromises of 2015
- Types of WordPress Caching
- Using WP-CLI with WebHostingPeople shared hosting
- What is Permalink and the best practices
- Why Do WordPress Sites get Hacked and How to Prevent It?
- Why WordPress is the Best Blogging Platform?
- Why You Should Manually Install WordPress Instead of Using Fantastico (and How to Do It)
- WooCommerce a Free WordPress Plugin for eCommerce
- WordPress – Changing Site URL and Home Settings
- WordPress Backup Restoration from Softaculous
- WordPress Files and Directory Structure
- WordPress Redirection Using Plugins
- WP-CRON
- YoastSEO Sitemap XML 404 Not Found
- Show all articles (140) Collapse Articles
Dedicated Server
VPS Hosting
WebHostingPeople
- Discover What Makes WebHostingPeople a Global Leader in Web Hosting
- Find Out How WebHostingPeople Can Accelerate Your Small Business Success
- How does WebHostingPeople provide reliable web hosting services?
- How long have you been in business?
- How secure is WebHostingPeople's hosting platform?
- Is WebHostingPeople's Hosting Right for Beginners?
- What are the advantages of transferring my domain/website/web hosting to WebHostingPeople?
- Are WebHostingPeople's Hosting Services Suitable for Individuals with Limited Technical Expertise?
- Discover What Makes WebHostingPeople a Global Leader in Web Hosting
- Do you have a refund policy?
- Do you offer a trial period or a satisfaction guarantee?
- Find Out How WebHostingPeople Can Accelerate Your Small Business Success
- How does WebHostingPeople provide reliable web hosting services?
- How long have you been in business?
- How secure is WebHostingPeople's hosting platform?
- Is assistance available for migrating my website from another host to WebHostingPeople?
- Is It Possible to Purchase Hosting Separately from a Domain Name?
- Is it possible to upgrade my web hosting plan at a later time?
- Is WebHostingPeople's Hosting Right for Beginners?
- What are the advantages of transferring my domain/website/web hosting to WebHostingPeople?
- What are the available payment frequency options?
- What Are the Essential Features to Consider in a Web Hosting Service?
- What is the pricing for hosting a website in India?
- What is the quality of technical support provided by WebHostingPeople?
- What payment methods do you accept?
- What types of web hosting services do you provide?
- Show all articles (4) Collapse Articles
E-commerce
- A guide on modifying Magento website URLs
- Best Applications to Run E-commerce Websites
- Change Favicon in Magento2
- Change Magento Base URL without accessing Admin Dashboard
- Configure Different Payment Methods in WooCommerce
- Enable Admin Login Captcha in Magento2
- How to Reset Magento Admin Password
- The top 10 best content management systems in 2022!
- WooCommerce vs Shopify : The best E-commerce platforms
FTP Tutorial
- 6 Best SFTP Clients for Windows and Mac Users
- A guide on how to execute site-to-site file transfers using the FlashFXP FTP client
- How to Create and Manage FTP Accounts in VestaCP
- How to Enable FTP Access in WHM?
- How to Increase FTP Visible File Limits
- Install ProFTPD in Webmin
- What is the process for transferring WHM backups to a remote destination using FTP?
Websites Migration
- A guide on how to transfer email accounts from one cPanel to another cPanel
- cPanel to Webuzo Migration
- Fix : check_mysql Has Determined That There Are Corrupted Database Tables (eximstats)
- How can emails be migrated using imapsync?
- How to Create and Manage FTP Accounts in VestaCP
- How to Enable Remote MySQL Connection in WHM?
- How to Fix the Common MySQL Errors?
- How to upgrade the MariaDB or MySQL version in Linux
- Import data from cPanel
- InMotion Hosting to WebHostingPeople Migration
- Migrate accounts from cPanel to DirectAdmin
- Migrating from cPanel to CentOS Web Panel
- Migration from 1&1 to WebHostingPeople
- Migration from A2 Hosting to WebHostingPeople
- Migration from Arvixe to WebHostingPeople cPanel
- Migration from Contabo to WebHostingPeople cPanel
- Migration from FastComet to WebHostingPeople
- Migration from GreenGeeks to WebHostingPeople
- Migration from Hostinger to WebHostingPeople
- Migration from HostPapa to WebHostingPeople
- Migration from LiquidWeb to WebHostingPeople
- Migration from Media Temple to WebHostingPeople
- Migration from Namecheap to WebHostingPeople cPanel
- Migration from SiteBuilder to WebHostingPeople
- Migration from Web Hosting Hub to WebHostingPeople cPanel
- Migration of BlueHost to WebHostingPeople cPanel
- Migration of cPanel from HostMonster to WebHostingPeople
- Migration of JustHost to WebHostingPeople cPanel
- Moving from GoDaddy to WebHostingPeople
- Moving from HostGator to WebHostingPeople
- Moving from SiteGround to WebHostingPeople
- Mytop can be used to monitor MySQL.
- phpMyAdmin Performance Settings
- The migration of A Small Orange to WebHostingPeople cPanel
- Transferring a website to another host using cPanel
- What is the process for migrating emails using IMAP Copy?
- What is the process for transferring a cPanel account from WHM?
- Show all articles (22) Collapse Articles


